
Métiers de la data
Data
Que fait un data labeler ? Fiche Métier
Découvrir

FAUX
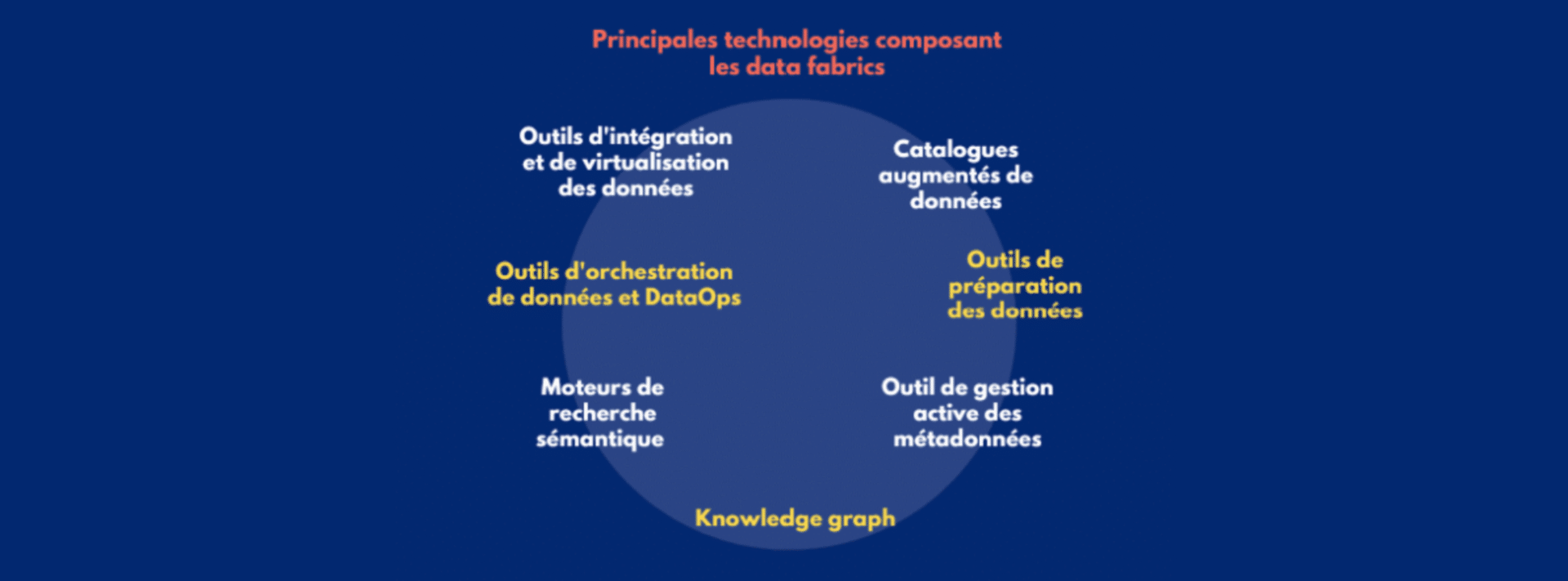
Une data fabric est une architecture composée de multiples briques technologiques visant à connecter le plus efficacement possible les sources de données et les utilisateurs. Des solutions délivrant des microservices se combinent pour progressivement former cette architecture. Par exemple, des technologies de knowledge graphs visant à connecter de manière très claire les données au sein des organisations seraient alimentés par des solutions IA de metadata management qui collecteraient et mettraient à jour automatiquement les métadonnées de l’entreprise. Il est à noter que ces solutions peuvent tout à la fois être disponibles on-premise, sur le cloud ou en hybride.
VRAI
L’adoption des solutions qui composent une data fabric (intégration, catalogues de données, gestion des métadonnées, préparation des données, orchestration, …) se fait de manière incrémentale suivant les cas d’usage de l’entreprise. Il est donc tout à fait possible de commencer par se doter d’une technologie puis en ajouter au fur et à mesure qu’elles deviennent nécessaires. C’est le principe de la « compossibilité » qui facilite l’adoption des outils et accélère leur opérationnalisation, avec des résultats commerciaux directement mesurables. Cette flexibilité fait ainsi partie intégrante du design data fabric.
FAUX
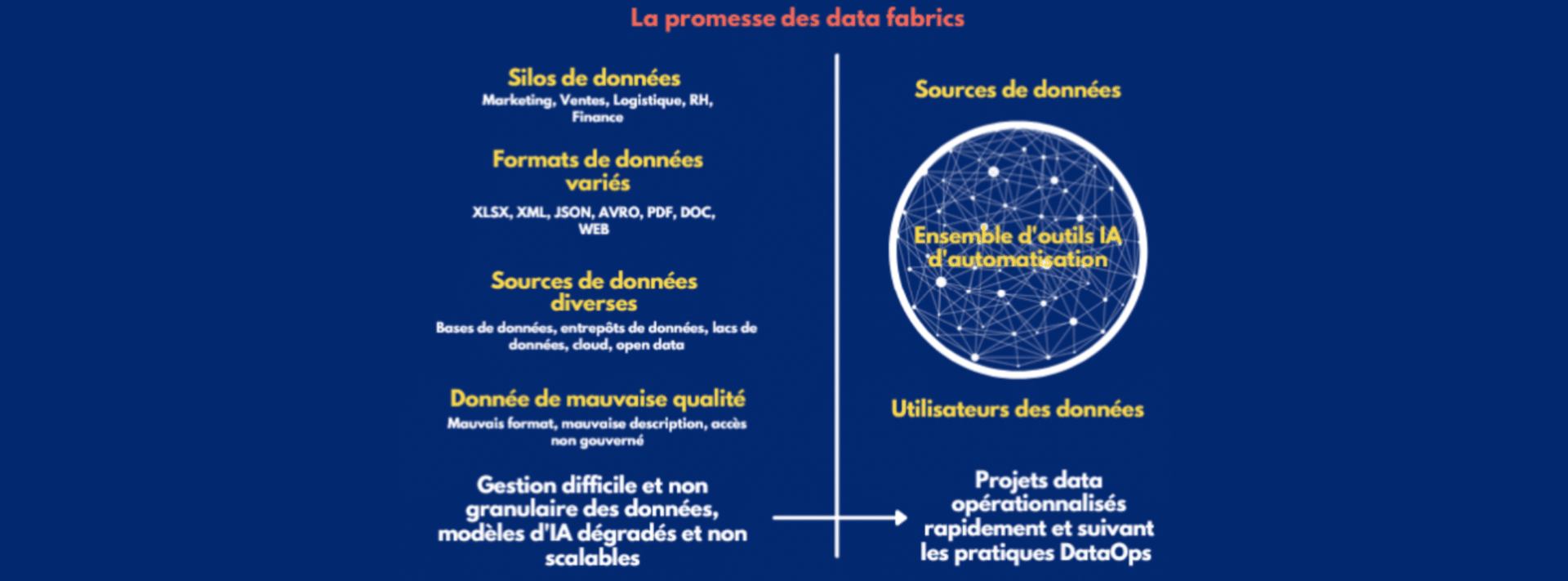
Les data warehouse et data lake sont des systèmes de gestion des données utilisés pour réaliser principalement de l’analyse de données. Les data hubs, quant à eux, sont une solution visant à désiloter au maximum les données (pour mieux comprendre les distinctions entre ces architectures, lire cet article). En revanche, les data fabrics sont beaucoup plus larges. Elles facilitent le partage de données, peuvent gérer tout type de données qu’elles soient transactionnelles ou opérationnelles, permettent l’intégration de données d’applications en provenance de clients, de fournisseurs et de partenaires commerciaux, etc. En fait, les data warehouses, data lakes et data hubs sont des composantes du design data fabric pour former un réseau efficient de données exploitables en temps réel par l’entreprise.
VRAI
Un des points clés des data fabrics est qu’elle se compose d’outils venant automatiser les tâches manuelles de gestion des données très coûteuses en temps et en ressources. Les solutions d’automatisation basées sur l’intelligence artificielle, et en particulier l’apprentissage machine (machine learning) et le traitement du langage naturel (NLP pour natural langage processing), sont donc essentielles au sein des data fabrics. Plusieurs d’entre eux pourront se combiner comme les catalogues de données augmentés, les outils de gestion active des métadonnées, les plateformes de préparation automatique des données, etc. Cette automatisation a pour finalité une accélération forte de l’opérationnalisation de tous les projets des entreprises. Puisque nombre de tâches d’intégration, d’harmonisation et de connection des données seront réalisées très rapidement, les utilisateurs pourront alors se concentrer sur la valeur ajoutée des projets : la compréhension des enjeux business et la prise de décision qui en découle.
FAUX
Au contraire, le design data fabric vise à rendre autonome toute personne qui travaille sur les données de l’entreprise. Cela sera rendu possible notamment grâce à une gouvernance des données maîtrisée et granulaire, c’est-à-dire où l’accès à un fichier voire une cellule dans un fichier sera contrôlé pour chaque utilisateur (grâce à des techniques de data masking par exemple). D’autre part, implémenter une data fabrics nécessite de travailler selon les principes DataOps. Il s’agit d’une approche collaborative (inspirée du DevOps qui a fait ses preuves dans le développement de logiciels) qui permet un dialogue permanent entre les équipes IT qui mettent en place des infrastructures de données (data engineers, data stewards, data architects), les équipes opérationnelles qui les exploitent (business analysts, product managers, …) et les clients ou autres parties prenantes à qui sont délivrés les résultats.
Ainsi, pour sélectionner les bonnes technologies qui vont venir composer la data fabric, il est très important de bien comprendre les cas d’usage business auxquelles elle va répondre et donc d’impliquer des experts métiers qui vont quotidiennement l’utiliser. Pour ces derniers, les outils no-code, qui ne nécessitent pas de compétence en programmation, sont particulièrement adaptés.
FAUX
S’il est vrai qu’adopter le design data fabrics nécessite un changement culturel, il est aussi conçu pour s’appuyer sur les outils déjà présents au sein des entreprises. Souvent, le principal problème auquel ces dernières font face est qu’elles collectent et exploitent leurs données dans des silos en utilisant uniquement des méthodes traditionnelles d’ETL (Extract – Transform – Load).
Les data fabrics prennent le contre-pied de cette approche et visent à connecter l’ensemble des données au sein des organisations et à les délivrer efficacement aux bonnes personnes. Il convient donc de commencer par travailler avec le CDO (Chief Data Officer) ou le CIO (Chief Information Officer) pour bien comprendre le concept de design data fabric, puis de rechercher les briques technologiques nécessaires pour y parvenir et enfin de mettre en place des pratiques DataOps de collaboration entre les équipes business et IT pour les opérationnaliser (voir notre article sur le sujet ici).
Sources :
– Gartner ; Sharat Menon, Ehtisham Zaidi, Mark Beyer ; Emerging Technologies: Data Fabric Is the Future of Data Management ; 4 décembre 2020.
– Gartner ; Mark Beyer, Ehtisham Zaidi, Donald Feinberg, Henry Cook, Jacob Orup Lund, Rita Sallam, Robert Thanaraj ; Top Trends in Data and Analytics for 2021: Data Fabric Is the Foundation ; 16 février 2021.
-Gartner ; Ehtisham Zaidi ; Data and Analytics Essentials: Data Fabric ; 13 juillet 2021.
